24/6/2022
-
min
A medida que crece la tendencia de los microservicios, se extiende el uso de contenedores. Para escalar su despliegue, es necesario orquestar todo el proceso y aquí es donde surge Kubernetes, una herramienta de moda entre los DevOps y una referencia en el mundo de la nube en los últimos años.

Hasta ahora, las empresas han construido sus aplicaciones, unas sobre otras, en sistemas monolíticos según sus nuevas necesidades de negocio, que desplegaban en las instalaciones o, en los últimos años, en la nube. La definición clásica de una aplicación monolítica se refiere a un conjunto de componentes totalmente acoplados que deben desarrollarse, desplegarse y gestionarse como una sola entidad. Prácticamente encajonada en un único proceso que es muy difícil de escalar, la única forma de hacerlo: verticalmente añadiendo más CPU (memoria).
En cambio, recientemente ha surgido el concepto de microservicios, que permite encapsular en contenedores varias aplicaciones pequeñas que pueden comunicarse entre sí para proporcionar una funcionalidad conjunta.
Hoy en día, todo parece dirigirse hacia la dockerización. La dockerización, como se conoce popularmente, consiste en empaquetar una aplicación de software para distribuirla y ejecutarla mediante el uso de contenedores.
Con este nuevo sistema, no es necesario modificar todo a la vez, ya que podemos actualizar cada uno de estos contenedores por separado y sustituirlos 'en caliente' en el entorno de producción, con las ventajas que ello conlleva a la hora de escalar.
A medida que el número de microservicios de nuestro sistema crece exponencialmente, su gestión se complica, ya que necesitamos un sistema de coordinación para el despliegue, la monitorización, la sustitución, el escalado automático y, en definitiva, la administración de los diferentes servicios que componen nuestra arquitectura distribuida.
Para resolver este reto, Google introdujo Kubernetes en 2014, que se ha convertido en el estándar de facto para implementar y desplegar aplicaciones distribuidas.
Kubernetes es un software de código abierto para desplegar y gestionar contenedores a gran escala. Kubernetes facilita la automatización y la configuración declarativa y nos ayuda a decidir en qué nodo se ejecutará cada contenedor, en función de los requisitos de recursos y otras limitaciones. Además, podemos mezclar cargas de trabajo críticas y de mejor esfuerzo para potenciar el ahorro de recursos, los despliegues y las reversiones automáticas.
Kubernetes se basa en la experiencia de Google en la ejecución de aplicaciones de producción a gran escala durante más de una década, junto con las mejores ideas y prácticas de la comunidad.
Kubernetes orquesta la infraestructura de computación, redes y almacenamiento para que las cargas de trabajo de los usuarios no tengan que hacerlo. Esto ofrece la simplicidad de la plataforma como servicio (PaaS) con la flexibilidad de la infraestructura como servicio (IaaS) y permite la portabilidad entre proveedores de infraestructura.

A medida que las aplicaciones crecen hasta abarcar múltiples contenedores desplegados en varios servidores, su gestión también se vuelve cada vez más compleja. Para controlar esta complejidad, Kubernetes ofrece una API de código abierto que controla cómo y dónde se ejecutan esos contenedores.
Kubernetes organiza clústeres de máquinas virtuales y programa los contenedores para que se ejecuten en esas máquinas en función de los recursos de procesamiento disponibles y de las necesidades de recursos de cada contenedor. Los contenedores se agrupan en pods (la unidad operativa básica de Kubernetes) que pueden escalarse hasta el estado deseado.
Kubernetes también gestiona automáticamente el descubrimiento de servicios, incorporando el equilibrio de carga, y hace un seguimiento de la asignación de recursos y los escala en función del uso del rendimiento. Además, comprueba el estado de los recursos individuales y permite que las aplicaciones se recuperen automáticamente reiniciando o replicando los contenedores.
La computación de borde es un modelo informático que consiste en procesar los datos en el borde de la red. Es decir, en nodos mucho más cercanos a donde se capturan los datos.
Este modelo unido a la Inteligencia Artificial está en plena expansión en los sectores industriales y se considera ya una de las tendencias tecnológicas con mayor impulso en 2022 como parte de las estrategias de digitalización industrial: La Inteligencia Artificial en el Edge (conocida como Edge AI). Esta tecnología se centra en el despliegue de algoritmos cerca de donde se originan los propios datos y se utilizan para sus cálculos. Para ello se utilizan nodos Edge, que se colocan y conectan localmente a las propias fuentes de datos.
Sectores como el Distribución de electricidad o la Industria del Agua están inmersos en procesos de transformación digital de gran parte de su negocio y la Edge AI es un habilitador para que estos procesos se lleven a cabo. Es en estos entornos donde, para el desarrollo y despliegue de algoritmos de explotación de datos, se ha generalizado el uso de contenedores.
Sin embargo, trabajar con contenedores en entornos distribuidos y a menudo remotos, como proponen los modelos de Edge Computing o Edge AI, requiere una herramienta que permita controlar todo el ciclo de vida de los nodos edge y la inteligencia que se ejecuta en ellos.

A medida que las aplicaciones y la computación en contenedores se extienden al borde, surge la misma necesidad de gestión para el escalado que Kubernetes resuelve en la nube. Las distribuciones ligeras de Kubernetes son ahora necesarias para la computación de borde, ya que cada vez más organizaciones empujan las cargas de trabajo más cerca de las aplicaciones y dispositivos que generan datos.
Barbara, la plataforma de edge computing industrial cibersegura, permite a las organizaciones ejecutar contenedores en el borde para maximizar los recursos y facilitar las pruebas, además de proporcionar la capacidad de que los equipos de DevOps se muevan con mayor rapidez y eficiencia.
Con un fuerte enfoque en lo que las organizaciones necesitan saber desde una perspectiva de plataforma, red e infraestructura, Barbara se posiciona como líder en la orquestación de aplicaciones en el Edge.
Barbara Edge es capaz de orquestar contenedores en varios hosts, hacer un mejor uso del hardware para maximizar los recursos necesarios para ejecutar las aplicaciones empresariales, y controlar y automatizar las implementaciones y actualizaciones de las aplicaciones.
Para agilizar el trabajo de despliegue y ejecución de aplicaciones en el Edge a gran escala, es imprescindible contar con una herramienta como Barbara que permita realizar al menos las siguientes acciones de forma segura:
Con la plataforma Barbara, las empresas pueden gobernar de forma segura toda la inteligencia distribuida en los nodos Edge, facilitando el despliegue, la depuración y la actualización de las aplicaciones que los equipos de Data Scientists han desarrollado.
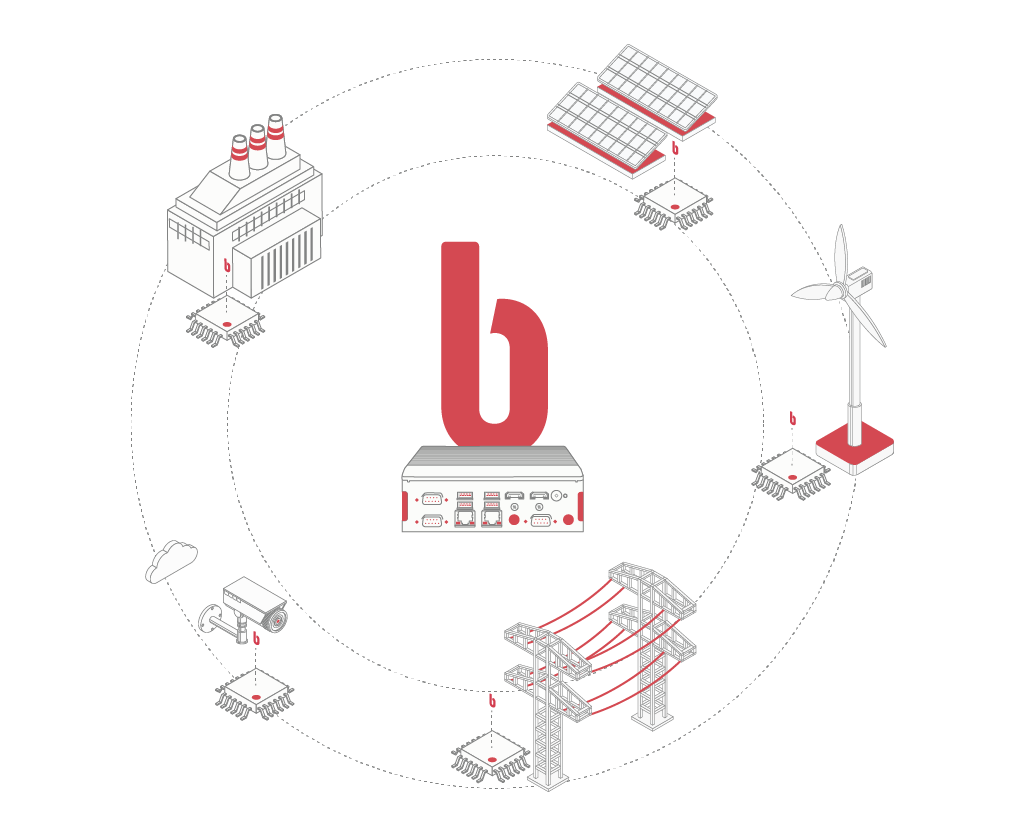
Mantener las aplicaciones en contenedores en funcionamiento puede ser complejo, porque a menudo incluyen muchos contenedores desplegados en diferentes máquinas. Barbara le permite empujar esos contenedores al estado deseado y gestionar sus ciclos de vida de una manera portátil, escalable y extensible.
Además, Barbara le permite añadir un control total sobre el desarrollo, las operaciones y la seguridad, lo que le permite desplegar las actualizaciones más rápidamente, sin comprometer la seguridad o la fiabilidad, y ahorrar tiempo en la gestión de la infraestructura, lo que equivale a un ahorro de costes.
Si estás trabajando en el despliegue de aplicaciones en el Edge en entornos industriales y quieres que te mostremos cómo nuestra plataforma puede ayudarte en el proceso, no dudes en pedirnos una demo.

La mayoría de las empresas industriales (hasta un 77% según un estudio del año pasado de IBM) están trabajando o planean trabajar con IA y Machine Learning como medio para optimizar sus operaciones o habilitar nuevas fuentes de ingresos. Y Machine Learning Operations (MLOps) se está convirtiendo en el paradigma como marco de trabajo para los equipos de Datos e Infraestructura implicados.

En la fabricación industrial, la industria cementera destaca por su considerable impacto medioambiental y su elevado consumo de energía. En medio de la creciente preocupación por el medio ambiente y el impulso a la sostenibilidad, la computación de borde presenta soluciones innovadoras para mejorar la eficiencia de la cadena de suministro, la sostenibilidad, la conservación de la energía y la trazabilidad de los productos.

Según Gartner, "La oferta de tecnología o servicio debe ser innovadora, impactante y estar disponible para su compra para un Cool Vendor." Con Barbara, las empresas pueden desplegar, ejecutar y gestionar sus modelos en ubicaciones distribuidas, tan fácilmente como en la nube.




